1 写在前面
光学字符识别(Optical Character Recognition,OCR)是计算机视觉与模式识别领域的重要研究方向,其核心目标在于将图像中的文本信息自动转换为可编辑、可检索的结构化文本。随着深度学习与大规模预训练模型的发展,OCR 技术已从以规则与特征工程为主的传统方法,逐步演进为以端到端学习为核心的深度学习范式。近期,DeepSeek 团队提出了 DeepSeek-OCR,通过“用更少的视觉 token 表达更多页面信息”的思路,在识别精度与上下文效率之间取得了较好的平衡,这一点在实际使用中非常有吸引力。
本文结合个人学习过程,对 OCR 技术的基本背景进行简要回顾,并重点梳理 DeepSeek-OCR 的设计动机、整体架构及其在视觉 token 压缩方面的特点,同时与常见的视觉语言模型(VLM)方案进行对比,供感兴趣的读者参考。
2 OCR 技术概述
2.1 OCR 的基本流程
典型 OCR 系统通常包括以下几个关键步骤:
-
图像预处理:对输入图像进行去噪、灰度化、归一化等操作,以提升后续处理的稳定性。
-
文本检测:定位图像中可能包含文本的区域,区分“有字”与“无字”区域。
-
文字识别:将检测到的文本区域映射为具体字符序列,实现从像素到符号的转换。
-
版面与后处理:进行错误纠正、段落恢复及版式重建,以输出更符合人类阅读习惯的文本结果。
2.2 传统 OCR 与深度学习 OCR 的一些区别
传统 OCR 方法主要依赖图像处理与统计学习技术,通过人工设计的特征(如边缘、线段、连通域等)完成字符识别。这类方法在字体规范、图像清晰的场景下具有较好表现,但对复杂版面与噪声较为敏感。
相比之下,深度学习 OCR 通常采用卷积神经网络(CNN)或 Transformer 架构,在大规模标注数据的驱动下直接学习从像素到字符类别的映射关系。同时,模型还能够隐式建模字符、段落、表格及公式之间的空间与语义关系,从而在复杂场景中显著提升识别鲁棒性。值得注意的是,当前主流深度学习 OCR 系统往往仍在预处理阶段部分依赖传统方法,以实现效率与精度的折中。
3 DeepSeek-OCR 的核心思想与实验动机
根据 DeepSeek 公布的实验结果可以看到:当文本 token 数量与视觉 token 数量之比控制在一定范围内时,OCR 解码精度可维持在较高水平。具体而言,当文本 token 数量不超过视觉 token 的 10 倍(约 10× 压缩比)时,整体 OCR 准确率可达约 97%;即使在约 20× 压缩比条件下,准确率仍可保持在 60% 左右。
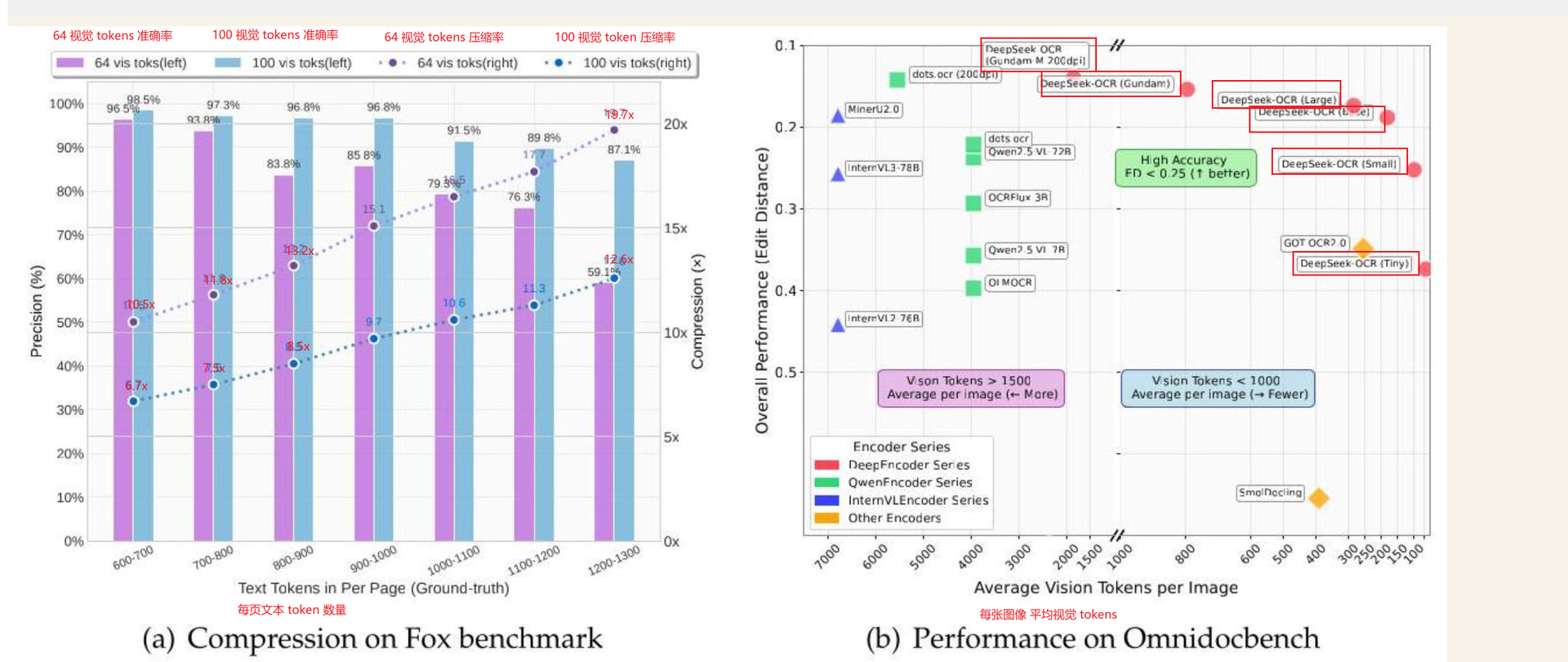
在多模态大模型中,上下文长度本身就是一种非常稀缺的资源。无论是文本 token 还是视觉 token,均会占用同等的上下文位置。因此,通过更少的视觉 token 表达尽可能丰富的页面信息,本质上是在压缩序列长度,从而显著提升模型在 OCR 场景下的整体效率。这一观察构成了 DeepSeek-OCR 设计的核心动机。
4 DeepSeek-OCR 的整体架构
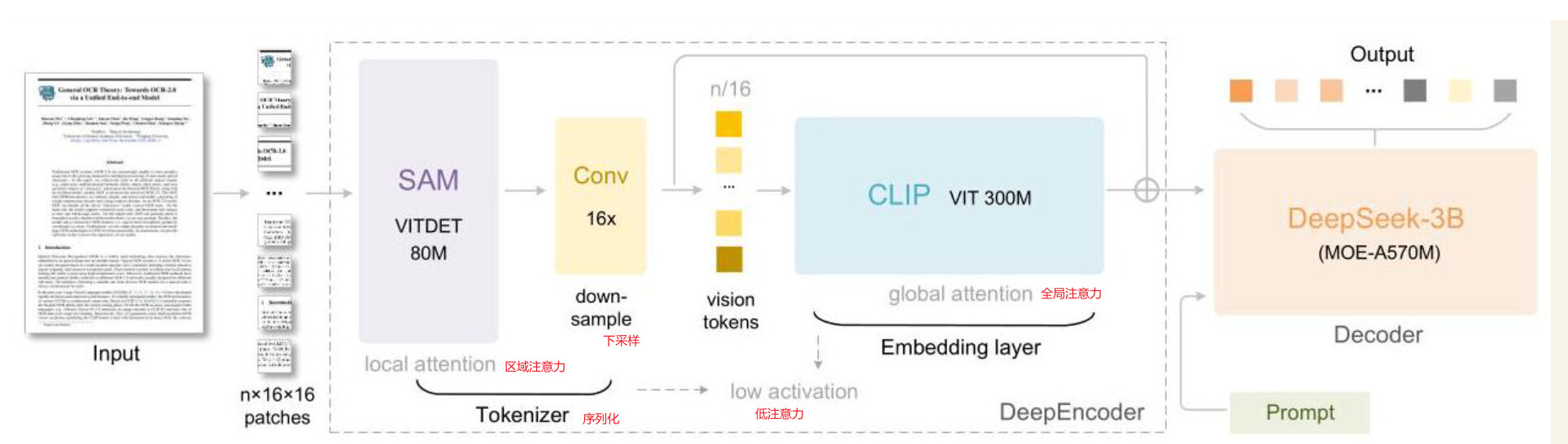
4.1 DeepEncoder:如何高效表示整页图像
DeepSeek-OCR 以视觉嵌入语言模型 DeepEncoder 作为核心编码模块。DeepEncoder 采用双路编码结构:
- SAM 编码分支 :通过窗口注意力机制捕获高分辨率的局部细节信息,尤其适用于小字号文本、细线条与局部结构。
- CLIP 编码分支 :利用全局注意力提取页面级语义特征,以建模整体布局与跨区域语义关系。
这两路特征在功能上相互补充,使模型能够在有限数量的视觉 token 中保留尽可能多的有效信息。
4.2 解码器:DeepSeek-3B-MoE
在解码阶段,DeepSeek-OCR 采用 DeepSeek-3B-MoE 作为语言模型解码器。该模型直接读取 DeepEncoder 输出的视觉 token,并生成对应的文本或结构化标记(如 Markdown、HTML、LaTeX 及表格标注)。整体流程可概括为:
图像 → 视觉 token(DeepEncoder) → 文本/结构化输出(DeepSeek-3B-MoE)
这一端到端范式在减少中间步骤的同时,也降低了对复杂后处理流水线的依赖。
5 与常见 VLM 架构的简单对比
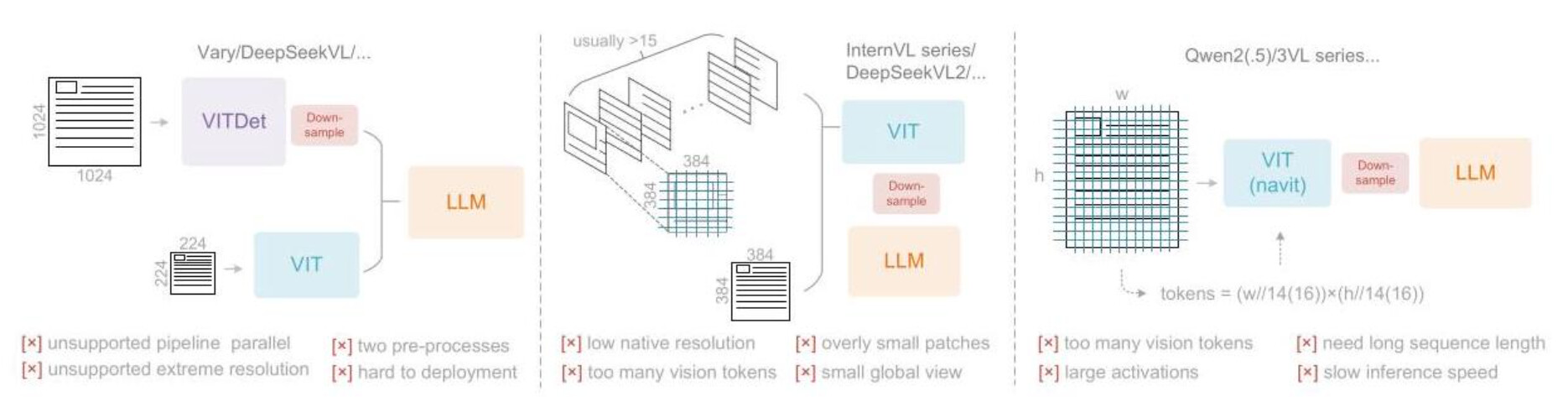
5.1 双塔结构(局部 + 全局)
以 Vary 系列模型为代表,双塔结构通常由“局部细节塔”和“全局语义塔”组成,分别负责区域级信息与页面级信息的提取。其优势在于能够兼顾细节与全局语义,对公式、表格与小字具有较好适应性;但其缺点在于工程复杂度高、推理链路冗长,且在超大页面场景下并行效率受限。
5.2 块切分处理方法
以 InternVL2.0 为代表,该方法将大图切分为多个固定分辨率的子块,并将所有子块的视觉 token 拼接后输入 LLM。其实现简单、易于并行,适合处理超大分辨率页面;但单块分辨率受限,小字信息易丢失,同时 token 数量随块数线性增长,导致序列长度显著增加。
5.3 自适应分辨率编码方案
Qwen2-VL 采用整图一次性编码的自适应分辨率策略,通过卷积映射使视觉 token 数量随分辨率动态变化。该方法在统一视野下同时保留细节与全局信息,但在高分辨率输入下易引发 token 爆炸,从而带来显著的计算与显存开销。
6 DeepEncoder 的分辨率与 token 设计

为支持不同 OCR 场景下的视觉 token 控制需求,DeepEncoder 在设计阶段引入多种分辨率模式,包括 Tiny、Small、Base 与 Large 四种原生模式,以及两种动态分辨率模式。不同模式通过下采样与 padding 策略,在不同比例的精度与效率之间提供灵活权衡。
需要指出的是,Tiny 与 Small 模式通常通过 resize 操作对图像进行拉伸或压缩,可能引入形变,不适用于小字密集或结构复杂的页面;而 Base 与 Large 模式主要通过 padding 对齐分辨率,在保持原始宽高比的同时提升细节保真度,但相应地增加了计算成本。
7 小结与一些个人理解
总体而言,DeepSeek-OCR 通过引入视觉信息压缩与高效编码机制,在有限上下文长度约束下实现了高精度 OCR 解码,为多模态大模型在文档理解与结构化信息抽取中的应用提供了新的技术路径。其在视觉 token 利用率方面相较于传统流水线 OCR 与部分端到端模型展现出明显优势。
需要说明的是,本文内容主要基于公开资料以及个人学习过程中的理解,难免存在不够严谨或理解偏差的地方,欢迎指正与讨论。后续也会在继续学习的基础上,对 DeepSeek-OCR 的细节与适用场景进行进一步补充。