链接: https://pan.baidu.com/s/16mvrQSyt-bwkUD2wJSLILg
常见问题
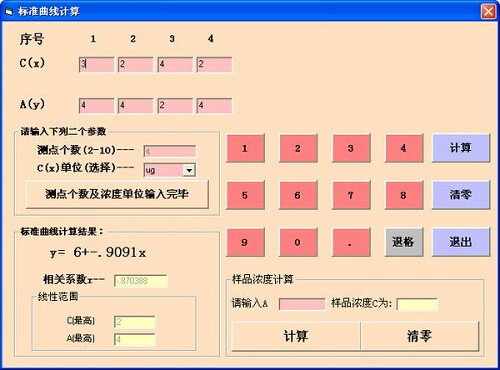
Q1:标准曲线计算到底在算什么?
A:本质是回归拟合。你有一组标准品数据:
- x:浓度/含量(已知)
- y:仪器响应/吸光度/Ct/峰面积(测得)
拟合出函数 $ y=f(x) $(或反过来),然后用未知样本的 y 反推 x。
Q2:线性标准曲线怎么写?R²越大越好吗?
A:最常见线性模型:
- y=ax+b
评价常看 R²、残差分布、线性范围、重复性。
R²高不等于正确:若高浓度点“压住”回归、低浓度误差很大,定量仍可能偏。更推荐同时看: - 残差是否随机(有无系统性弯曲)
- 是否需要加权回归(如 1/x 或 1/x²)
- 回算浓度的相对误差是否在可接受范围
Q3:什么时候用 4PL/5PL(ELISA常见)?
A:当响应-浓度呈S型(尤其免疫学/ELISA)时,线性不合适。
- 4PL:对称S型
- 5PL:允许不对称,更贴合部分试剂盒曲线
通常软件可直接选择模型并输出回算结果与拟合优度。
Q4:标准曲线点数、重复、范围怎么设?
A:常见建议(按经验值,具体按规范/试剂盒/领域标准):
- 点数:5–8个浓度梯度更稳
- 重复:每点 2–3次
- 范围:覆盖样本预期浓度并留裕度(别让样本落在外推区)
Q5:样本落在线性范围外怎么办?
A:优先:
- 稀释/浓缩后重测(最可靠)
- 不建议“硬外推”,除非方法学验证明确允许且误差可控
软件/工具
1) GraphPad Prism(生物/医学常用)
- 用途:标准曲线拟合(线性、非线性、4PL/5PL)、ELISA定量、图表输出
- 使用方式:导入标准品与样本数据 → 选择模型(线性/4PL/5PL等)→ 自动回算未知浓度与报告
- 面向群体:生物实验室、医学生物统计、药理/免疫学
- 适用场景:ELISA、酶活曲线、细胞实验定量、方法学图形化展示
- 教程/官网: https://www.graphpad.com/guides/prism/
2) Microsoft Excel / WPS 表格(通用型)
- 用途:线性回归、加权回归(需手动)、简单标准曲线与回算
- 使用方式:散点图→添加趋势线(线性)或用 LINEST/回归工具→用公式反算浓度
- 面向群体:所有需要快速出结果的人(入门/应急)
- 适用场景:简单线性标准曲线、初筛数据、教学演示
- Excel函数参考: LINEST 函数 - Microsoft 支持
3) R(统计更强,适合可重复科研)
- 用途:线性/非线性拟合、加权回归、批量回算、可复现脚本化分析
- 使用方式:lm/nls 等建模 → 生成预测与置信区间 → 输出报告(RMarkdown/Quarto)
- 面向群体:需要批处理、严谨统计、可复现实验流程的科研人员
- 适用场景:qPCR标准曲线评估、方法学验证、批量样本定量、审计追溯
- 官网: https://www.r-project.org/
- R入门: CRAN: Manuals
4) Python(自动化与管线整合)
- 用途:拟合模型、批量处理、多板数据解析、与LIMS/仪器数据联动
- 使用方式:pandas读表→scipy/statsmodels拟合→生成回算结果与图表
- 面向群体:数据量大、需要自动化的实验室/生信/计算团队
- 适用场景:高通量检测、自动出报告、跨项目复用脚本
- SciPy: https://scipy.org/
- statsmodels: https://www.statsmodels.org/
论坛式小抄:标准曲线计算输出建议
- 拟合模型:线性 / 4PL / 5PL / 加权方式
- 线性范围:最低点-最高点(注明剔除点与原因)
- 拟合指标:R²(线性)、残差/拟合优度(非线性常用)
- 回算误差:标准点回算浓度的偏差(%)
- 样本处理:稀释倍数、外推说明、异常点处理规则